Xyna Shared Resource Management
Xyna Bulletin #30
Liebe Freunde, Partner und Kunden von Xyna,
heute wollen wir uns einem betriebsnahen Thema widmen, damit auch die technisch interessierte Leserschaft des Bulletins neugierig und interessiert bleibt: es geht um das neue Xyna Shared Resource Management (Xyna SRM).
Kurz und knapp: ein Mechanismus zur Sicherstellung der Konsistenz von System- und Infrastruktur-Ressourcen in einem verteilten "Cloud-native" Szenario. Also einem betrieblichen Set-Up, in dem die Systemlast auf lose gekoppelte Knoten (Container, Worker Nodes) verteilt wird, die voneinander unabhängig laufen, aber dennoch einen zentralen Mechanismus benötigen, um Kapazitäten, Vetos und IDs kooperativ zu nutzen.
Bevor es losgeht, schnell noch ein Hinweis auf die bevorstehende TM Forum dtw Ignite! Konferenz in Kopenhagen vom 23.-25. Juni.

Wir werden in diesem Jahr mit einem Messestand (booth 323), einem Catalyst-Projekt (URN C26.0.921, Kiosk i2.8) und einem Industry Showcase (TMF Stage) vertreten sein. Und natürlich mit einem freundlichen und kompetenten Team vor Ort. Mehr dazu im nächsten Bulletin.
Viel Spaß beim Lesen!
::
Xyna Shared Resource Management (Xyna SRM)
Ausgangspunkt: „The Migration Shift“ / Moving from VMware to Kubernetes
Über viele Jahre hinweg war VMware mit der vSphere-Plattform und dem ESXi-Hypervisor quasi der de-facto-Standard für Virtualisierung. Zumindest sind 90% unserer Projekte in einem VMware Set-Up gelaufen - und das sehr erfolgreich, denn aus einer nüchternen betriebstechnischen Perspektive heraus ist gegen eine Virtualisierung mit VMs eigentlich nichts zu sagen.

Nun hat sich die Welt jedoch dazu entschieden, aus [ebenfalls gut nachvollziehbaren Gründen] auf „Cloud-native“-Infrastrukturen zu setzen. Worunter meistens Architekturen auf Basis von Containern (häufig Docker) verstanden werden, die über Orchestrator-Plattformen wie Kubernetes oder OpenShift gemanaged und betrieben werden. Das hat kommerzielle Gründe (Stichwort Broadcom, Lizenzmodell) - aber auch technische, wie Kernel Sharing, Skalierbarkeit, Ressourceneffizienz oder schnellere Startzeiten.
Warum erzählen wir das?
Xyna-basierte Anwendungen sind gerne wichtige OSS-Systeme mit entsprechenden Anforderungen an Verfügbarkeit und Lastverteilung durch horizontale Skalierbarkeit. Für das VM-Zeitalter hatte Xyna hierfür verschiedene „Cluster Provider“ (RMI, Oracle RAC, XSOR) im Angebot, um Cluster-Architekturen (High Availablity, Shared Nothing, etc.) zu realisieren.
Grundsätzlich sehr leistungsfähig, sind die Cluster Provider jedoch darauf angewiesen, dass das Cluster-Layout (Anzahl Knoten + Aufgaben) bekannt ist. Es sind quasi statische Aufbauten, was durch den VM-Ansatz sowohl geboten als auch sinnvoll umzusetzen ist.
Herausforderung: verteilte Ressourcen bei Cloud-native
In einem Cloud-native Szenario geht diese „VM-Statik" nun verloren bzw. wird ersetzt durch „Container-Flexibilität": der Orchestrator (Kubernetes) möchte in Abhängigkeit von Last oder anderen betrieblichen Gegebenheiten (z.B. Ressourcenverteilung) die Menge an Containern (Worker Nodes) flexibel skalieren:
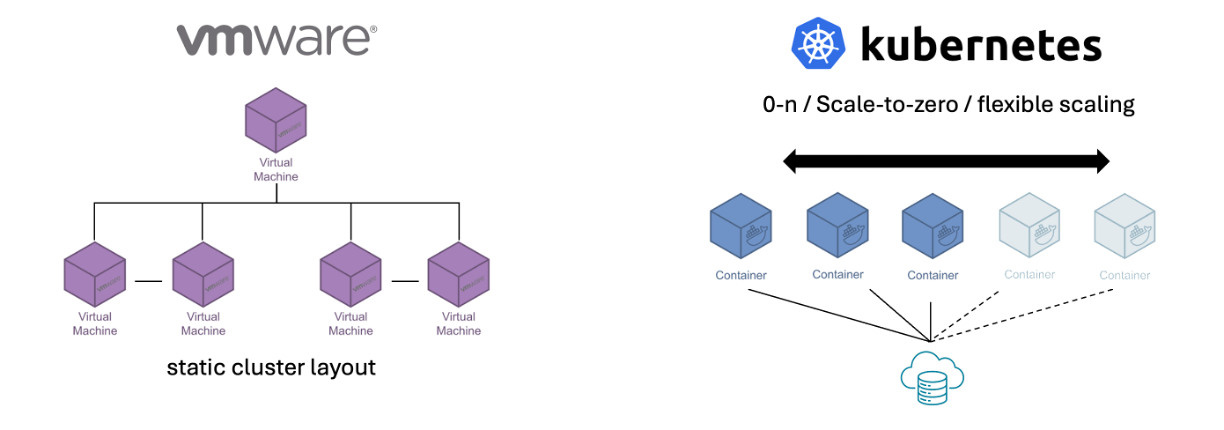
Das ist erstmal eine feine Sache. Und wenn sich die auf die Container zu verteilenden Aufgaben strukturieren und separieren lassen, ist die Steuerung über den Orchestrator i.d.R. gut realisierbar. Nun gibt es aber auch anwendungsbezogene Informationen, die über den gesamten Verbund hinweg einzigartig bzw. in ihrer Menge begrenzt sind oder eindeutig nummeriert werden müssen. Für Xyna sind das insbesondere Vetos, Kapazitäten und IDs.
Kleine Erinnerung für alle, die leider nicht jeden Tag mit Xyna arbeiten dürfen: Vetos und Kapazitäten dienen zur Nebenläufigkeitssteuerung im Xyna Scheduler. Mit Vetos lässt sich z.B. verhindern, dass zwei Aufträge gleichzeitig auf einem Endgerät ausgeführt werden. Und mit Hilfe von Kapazitäten kann die Menge parallellaufender Aufträge begrenzt werden, um z.B. Zielobjekte mit Kapazitätsbegrenzung oder APIs vor Überlastsituationen zu schützen. IDs wiederum werden für verschiedene Zwecke genutzt, z.B. zur eindeutigen Bezeichnung von Auftragsinstanzen (Order ID).
Und genau hier kommt das Xyna Shared Resource Management ins Spiel.
Xyna SRM - Konsistenz in elastischen Umgebungen
Für Xyna SRM wurden einige neue Xyna-Komponenten entwickelt, die im Wesentlichen auf den Xyna Nodes (Containern) laufen. Sie sorgen dafür, dass für Vetos, Kapazitäten und IDs bei jeder Nutzung eine Abfrage an eine zentrale Datenbank stattfindet.
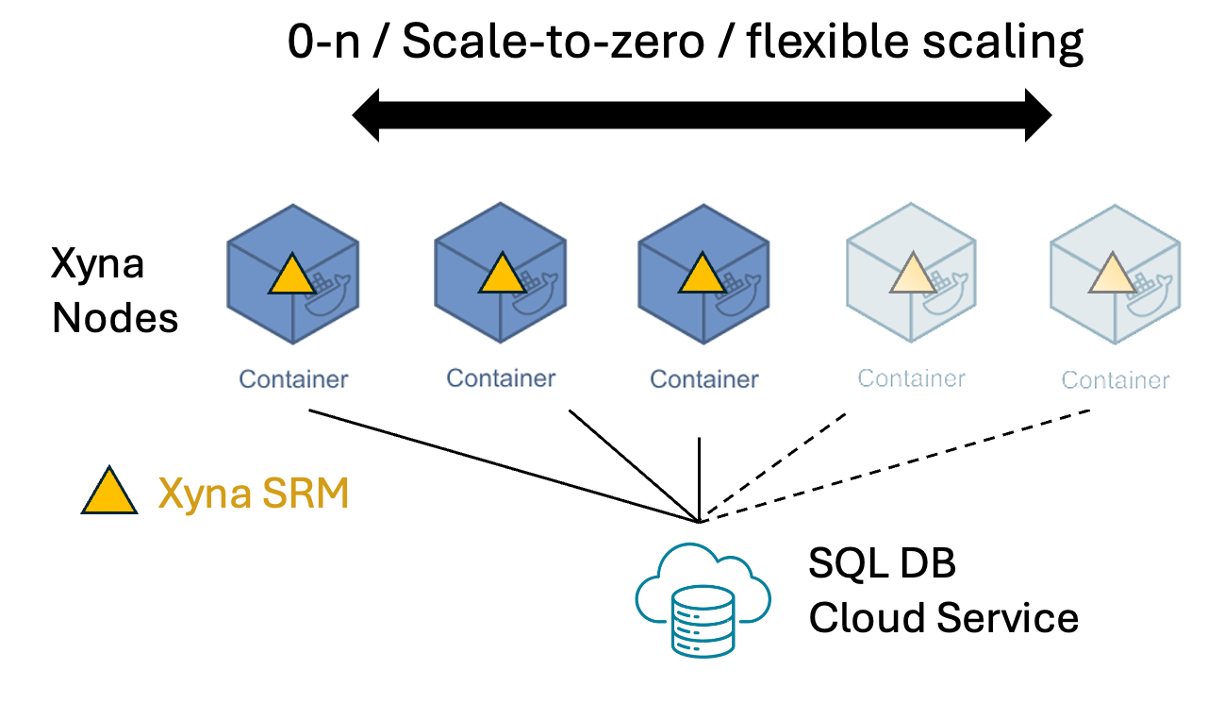
Diese zentrale Datenbank kann eine beliebige SQL-Datenbank sein, die z.B. als Cloud Service ebenfalls in Form eines Containers in der Kubernetes-Umgebung läuft. Im Gegensatz zu den flüchtigen Worker Nodes gilt hier jedoch: dieser DB-Service muss so konfiguriert werden, dass seine Verfügbarkeit immer dann sichergestellt ist, wenn zumindest ein Xyna Node laufen will. Wenn der Knoten immer verfügbar sein soll, bietet sich z.B. eine 2+1 HAaaS-Konfiguration an.
Die Funktionsweise von Xyna SRM lässt sich dann vereinfacht so zusammenfassen: immer, wenn ein Xyna Node eine Aktivität startet, die IDs, Vetos oder Kapazitäten nutzt, erfolgt eine Rücksprache mit der zentralen Datenbank. Robuste Algorithmen sorgen dafür, dass auch bei hohen Lastsituationen, dynamisch hinzukommenden bzw. wegfallenden Containern oder Kommunikationsfehlern keine Inkonsistenzen auftreten.
Und was bringt das alles?
Und warum braucht man das überhaupt?
Nun - wer sich schon einmal mit den Herausforderungen von parallelem Rechnen beschäftigt hat, dem dürfte klar sein, dass die koordinierte und kooperative Nutzung zentraler Informationsobjekte über verteilte Knoten hinweg keine ganz einfache Sache ist. Und da sprechen wir noch nicht über echte Kohärenz.
Dabei ist Xyna SRM nicht einfach ein weiterer Cluster-Provider, sondern eine komplett neue eigenständige Funktion zur Distribution und Synchronisierung von Ressourcen über lose gekoppelte Container.
Xyna SRM ermöglicht:
- Cloud-native Set-Ups für Xyna-basierte Anwendungen
- Dynamisches Skalieren von Xyna Nodes in einem Orchestrator
- Szenarien wie Scale-to-Zero oder FaaS Serverless Computing
- Hohe Verfügbarkeit von Anwendungen durch JIT-Provisionierung
Ziemlich cool. Und ziemlich leistungsfähig. Und erfordert (nichts ist umsonst), dass die Anwendung, die Xyna SRM nutzen will, in Bezug auf ihre Prozesslogik zur Auftragsverarbeitung auch entsprechend vorbereitet ist.
Wenn ihr dazu mit uns in Überlegungen einsteigen wollt: immer gerne.
Sprecht uns an!